A digital library for rare works and forgotten authors of Silver Age Spain
For this episode of our Local Time Machine Thursday (#LTMThursday), we had the pleasure to do a written interview with Maria Dolores Romero López who is a professor for Spanish literature at the Universidad Complutense in Madrid and directs the research group “La Otra Edad de Plata: Proyección Cultural y Legado Digital (LOEP) on the project Mnemosine, a Digital Library for Odd and Forgotten Literary Texts (1868-1939).
Original project title: Hacia la historia digital de La otra Edad de Plata: producción, almacenamiento, uso y difusión.

Time Machine: What was your initial idea for the project? Was there a particular spark that birthed the idea for this project?
María Dolores Romero López: To explain the initial spark for our project, allow me to make an excursion into the history of literature and how it not only reflects on but even more raises visions on libraries and archives:
Libraries have long been sites of individual and collective reference. There are public libraries and private collections; some occupy vast halls, and others are limited to a few shelves on a bookcase. Together, they pursue a shared objective though: To give visibility and provide a degree of spatial order to the chaotic mass of human knowledge.
Argentine writer Jorge Luis Borges (1899–1986) imagines in his fiction “La Biblioteca de Babel” (1941) that the universe is an expansive library and humanity its librarians. Borges’s library is a vivid metaphor for the pursuit of encyclopedic knowledge, a ‘catálogo de catálogos”’ or a glimpse of eternity and perfection. The library is not only a site or collection but also a process, a reiterative search for ourselves and for infinite knowledge, the ultimate purpose of which is to push the limits of human understanding.
A case in point is the “Mnemosyne Atlas” of the German Jewish art historian and cultural theorist Aby Warburg (1866–1929), who dedicated his life to collecting books and organizing them in a visionary manner. His library, begun in 1924, is radically different from any other, as its ‘volumes’ are panels of images that highlight the affinities between art, medicine, philosophy, and astrology. Warburg compiled over 2,000 images in symbolic constellations on more than 60 panels that juxtapose details of paintings with allegorical emblems or engravings of the circulation of blood through the body. In this way, historians and users of the atlas can access visions of the past through the multiple, crisscrossing paths of memory. Today the “Mnemosyne Atlas” inspires awe in those who see it in person. Moreover, its legacy endures thanks to the digital project of the Cornell University Library, “Mnemosyne, Meanderings through Aby Warburg’s Atlas”.
Borges makes clear that his library is ‘ilimitada y periódica’ (limitless and periodical), and Warburg designed his atlas to be open to continual expansion through the addition of new panels. The Library of Babel and the “Mnemosyne Atlas” thus embody what evolutionary biologist Richard Dawkins calls a ‘meme’, a cultural gene that self-replicates, spreads, and evolves from person to person, librarian to librarian.
The term ‘meme’ can be traced back to the beginning of the 20th century – a time far from digital technologies. Nowadays a meme is mainly known and popular in the digital environment. How does modern technology affect libraries when related to the idea of memes?
In the Digital Humanities, digital archives and libraries started as replicas of their analogue counterparts, but now they are coming into their own with the aid of technologies that allow for advanced searches, interoperability, and interactivity. These tools highlight the library-as-process even as they increasingly remove it from a fixed physical locale. Today, digital libraries are evolving towards models that approximate artificial intelligence, a development that will have enormous implications for future researchers. Librarians, Humanities scholars, and information scientists are asking what information should be made available digitally, how and where it should be stored, and how it can be accessed and integrated into teaching and research, the human ritual of replicating, and advancing knowledge. It is not enough for digital libraries to collect and store information; only access, use, and interpretation are capable of turning data into insight, and storage into memory.
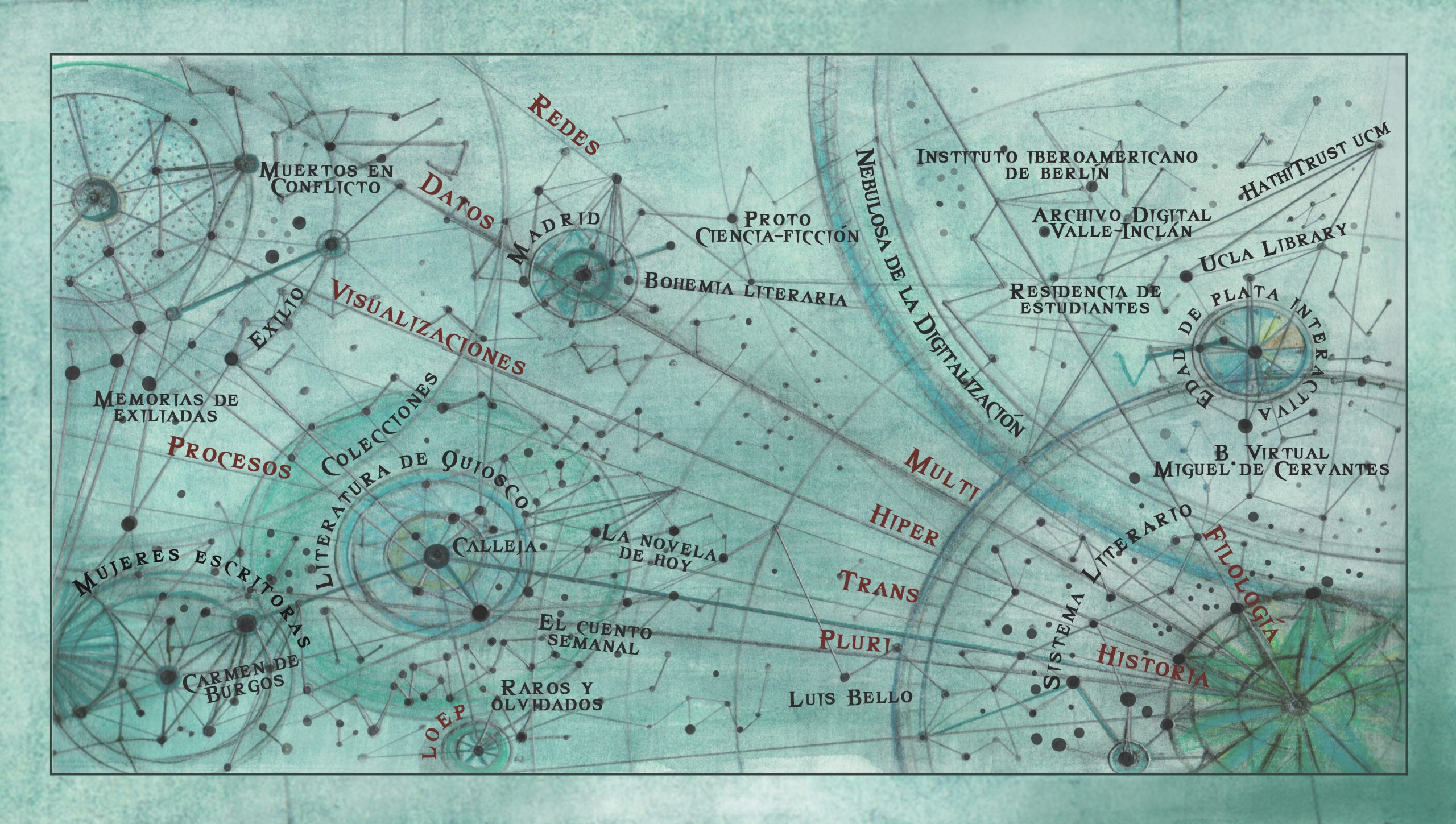
In this context, the original idea of the Mnemosine Digital Library comes from the research group “La otra Edad de Plata” at the Universidad Complutense de Madrid and its interest in the study of rare works and forgotten authors of Silver Age Spain. The label “raros” (rare and odd) as a critical term applied to Spanish literature dates to 1863, when Bartolomé José Gallardo published his “Ensayo de una biblioteca española de libros raros y curiosos” (Attempt at a Spanish Library of Odd and Curious Books). Over a century later, in 1964, Homero Serís published another such library under the title “Nuevo ensayo de una Biblioteca Española de libros raros y curiosos” (New Attempt at a Spanish Library of Odd and Curious Books). Together the two books exemplify the enlightened, rationalist impulse to produce a comprehensive literary history, not limited to the most glorious or canonical texts.
In this sense, they lay a foundation for the Mnemosine project. Unlike the volumes, however, Mnemosine does not include texts published prior to 1868 and does not focus specifically on ‘odd and curious’ literary works. Although this pair has met with some success, as witnessed in the long list of results for these search terms in the catalogue of the Biblioteca Nacional de España, Mnemosine values ‘forgotten’ over ‘curious’ documents. In modern times, the pair ‘odd and forgotten’ conveys complex cultural connotations referring less to documents with scarce circulation or impact than to texts whose aesthetic and ideological stances keep them from fitting into history or the canon with upper-case letters. It was Federico Carlos Sainz de Robles who advocated for the term ‘odd and forgotten’ to study Spanish literature of the first third of the twentieth century. In accordance with our time, the digital reconstruction of Spanish culture during the Silver Age seems necessary. This is one of the objectives for Mnemosine, a Digital Library for Odd and Forgotten Literary Texts (1868-1939), whose purpose is to select, categorize and make literary texts that belong to a forgotten repertoire visible in digital format in order to facilitate the historical review of the period.
Who were your project partners at the beginning and how has this consortium changed/expanded in the meantime?
Our Mnemosine project is the work of two research teams affiliated with the Universidad Complutense de Madrid and funded by the publicly subsidized national research project ‘Escritorios Electrónicos para las Literaturas’ (Digital Desktops for Literature). During its development, the research group “Literaturas Españolas y Europeas del Texto al Hipermedia” (LEETHI), a team focused on the digitization of Spanish and European literature, aspired to create an electronic library with digitized books. To this end, the group needed to delimit a field of study around a complex, rich, and diverse literary period, much like the one that had already been defined by the research group “La Otra Edad de Plata” (LOEP). Together, researchers from these two groups along with doctoral students in information technology and library science have been able to develop a library that constitutes an object of study in and of itself. And the LEETHI and LOEP research group collaborates with software engineers as a third research group, the research group on “Implementation of Language-Driven Software and Applications” (ILSA), also situated at the Universidad Complutense. The integrative spirit combining technology and humanistic knowledge permeates Mnemosine: Biblioteca Digital de la Otra Edad de Plata. The authors are collaborating on the design of ‘Clavy’, a software application calibrated to meet the needs of researchers.
Can you explain the Clavy tool a bit more – how does it work and which role does it play in the project? And within this context: How does your data storage work and how can the data be linked outward?
Clavy is an experimental platform for the construction of specialized, reconfigurable digital collections. Its fine-tuned navigation, filtering, and search capacities make it ideal for working with large quantities of densely interconnected data. Further, experts can use Clavy to build focused collections by importing information from different sources, customizing metadata models to specified ends, and presenting the resulting collections in ways that make them simple to navigate and connect with external sources. Our project uses Clavy to select, catalogue, and display a largely forgotten repertoire of Spanish literature published between 1868 and 1939. In so doing, the library lays the foundation for a revised literary history that recovers texts and creators that were more or less willfully excluded from the canon consolidated under Franco. Clavy facilitates the import, export, and edition of records in multiple formats such as MARC2145, as well as their integration into Mnemosine’s predesigned model with a view to their export into other compatible formats like XLS (Excel Binary File Format) or XML (Extensible Markup Language), or into other systems like OdA.46. Using Clavy, metadata for more than four thousand digitized objects from HathiTrust and the Biblioteca Digital Hispánica have already been imported into the Mnemosine database. Logically, the data from these sources were described in MARC21, following the rules for library catalogues. The outcome was foreseeable: In some cases, Mnemosine’s data model did not require the degree of detail furnished by MARC21, while in other cases it was necessary to incorporate new information absent from that format.
The data is accessible via the Clavy tool with the permission of the research groups.
What was your starting point for the project concerning available data? How did you get the idea to build a database of the data available? What content providers do you cooperate with?
The first version of the library is stored on the server of the Universidad Complutense de Madrid Library, itself linked to the collections of the digital library HathiTrust. In a search conducted in HathiTrust in 2012, the names, surnames, and pseudonyms of selected authors were used to locate a total of 2,873 digitized texts corresponding to ‘odd and forgotten’ writers. The Biblioteca Digital Hispánica, which serves as the access portal for the digital collections of the Biblioteca Nacional de España, provided 2,448 works by male authors and 1,017 works by female writers. We create the specific data regarding our research interest:
Who are your main content providers for the project? Do you keep this network expanding?
Yes, indeed – our content provider network grows continuously.
We started out with the data of HathiTrust and the Biblioteca Digital Hispánica. Nowadays we also include the data from the Instituto Iberoamericano in Berlin and the Online Archive of California.
Who would you say are your typical users?
We mainly have researchers of this particular era as users but also students at school and universities and the general public.
Has there been a particularly notable/memorable discovery on an author or literary work through Mnemosine?
Oh yes! Many forgotten authors have been promoted thanks to the Mnemosine database. The most important are women writers: Elena Fortún, Carmen de Burgos, Rosario Acuña, Aurora de Albornoz, Ángeles Vicente, Concepticón Arenal, Federica Montseny, Julia Asensi … just to mention a few. This lead us to organize the international congress “La mujer moderna, 1900-1939” which was received with great success by the public and the media.
